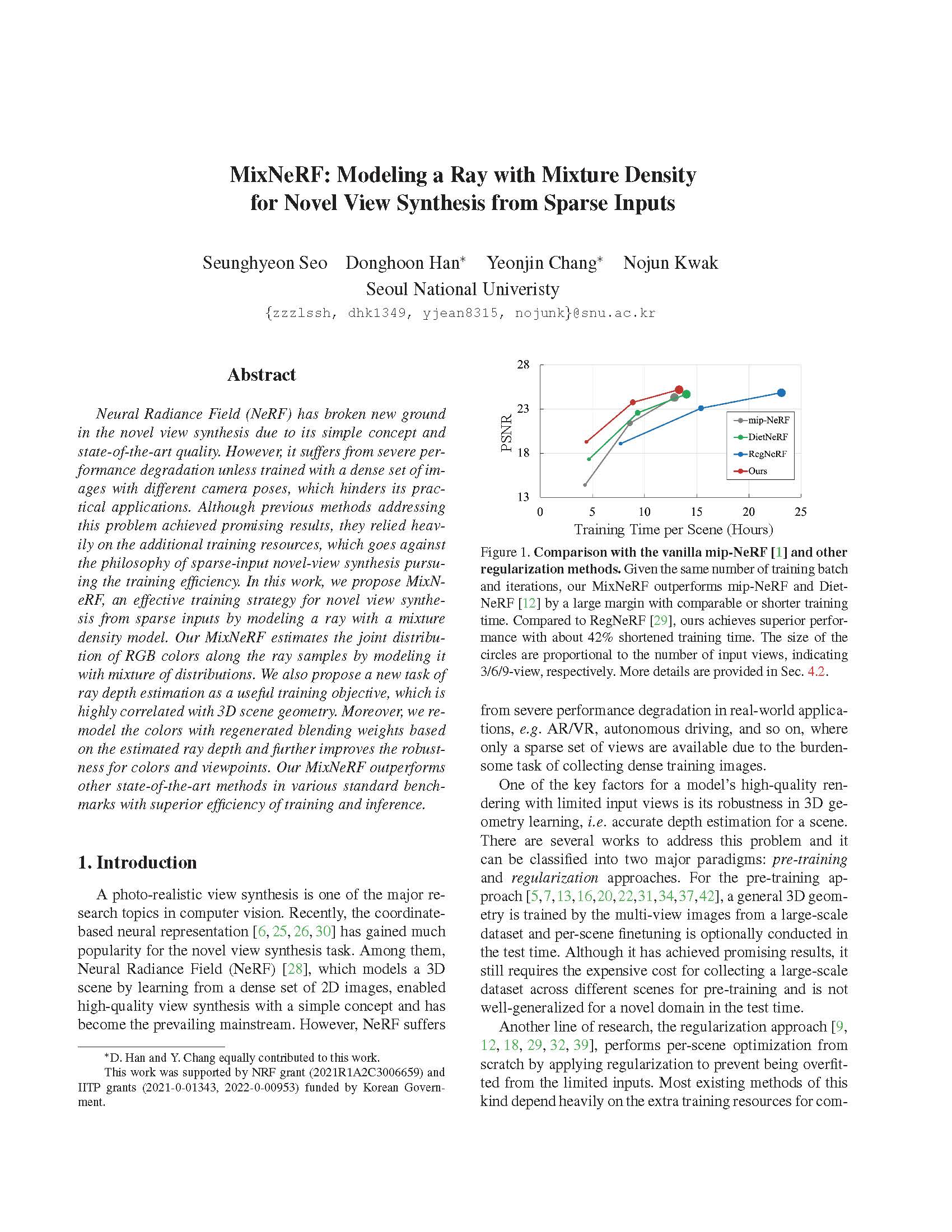
Abstract
Neural Radiance Field (NeRF) has broken new ground in the novel view synthesis due to its simple concept and state-of-the-art quality. However, it suffers from severe performance degradation unless trained with a dense set of images with different camera poses, which hinders its practical applications. Although previous methods addressing this problem achieved promising results, they relied heavily on the additional training resources, which goes against the philosophy of sparse-input novel-view synthesis pursuing the training efficiency. In this work, we propose MixNeRF, an effective training strategy for novel view synthesis from sparse inputs by modeling a ray with a mixture density model. Our MixNeRF estimates the joint distribution of RGB colors along the ray samples by modeling it with mixture of distributions. We also propose a new task of ray depth estimation as a useful training objective, which is highly correlated with 3D scene geometry. Moreover, we remodel the colors with regenerated blending weights based on the estimated ray depth and further improves the robustness for colors and viewpoints. Our MixNeRF outperforms other state-of-the-art methods in various standard benchmarks with superior efficiency of training and inference.
Video
Modeling a Ray with Mixture Density Model
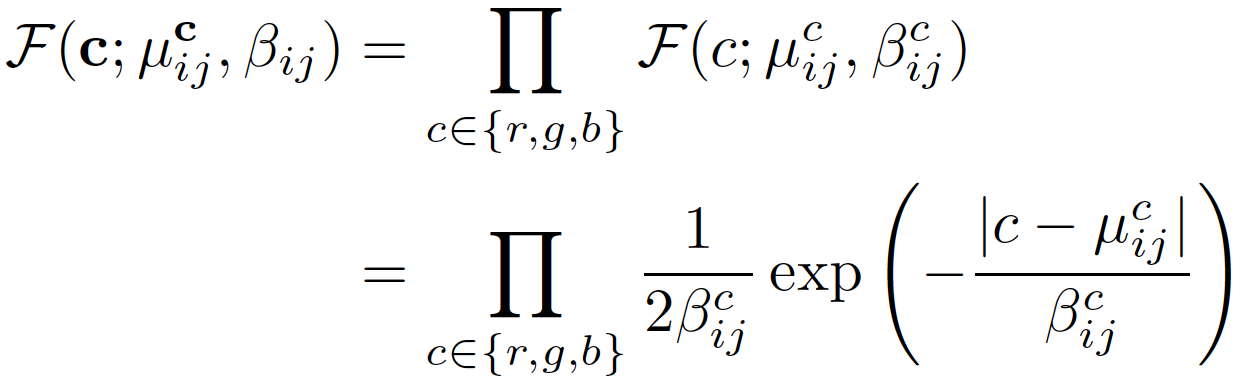
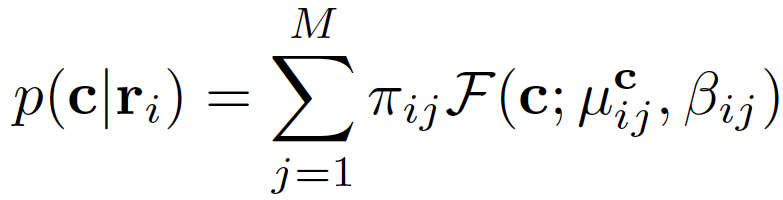
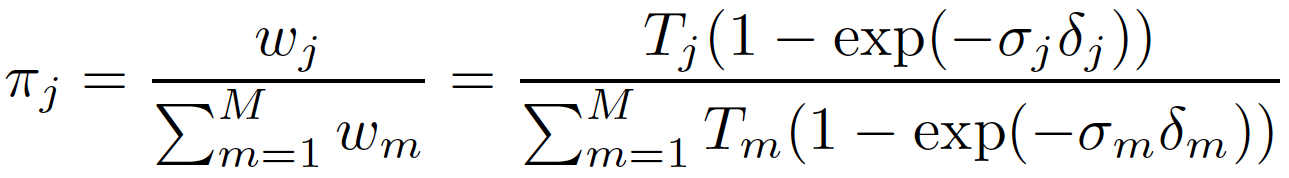
Depth Estimation by Mixture Density Model
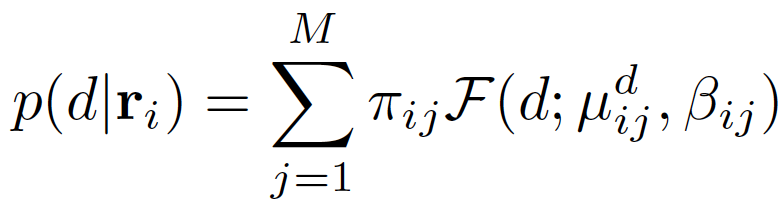
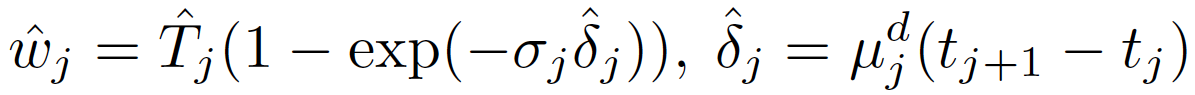
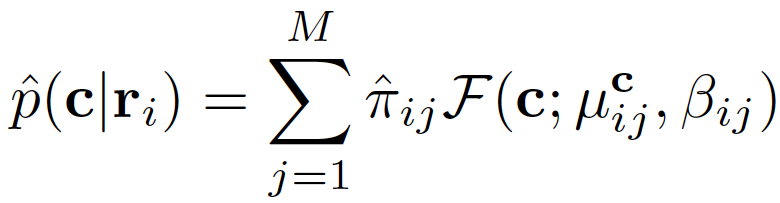
Benefit of Mixture Density Model

Depth Map Estimation
Efficiency in Training and Inference
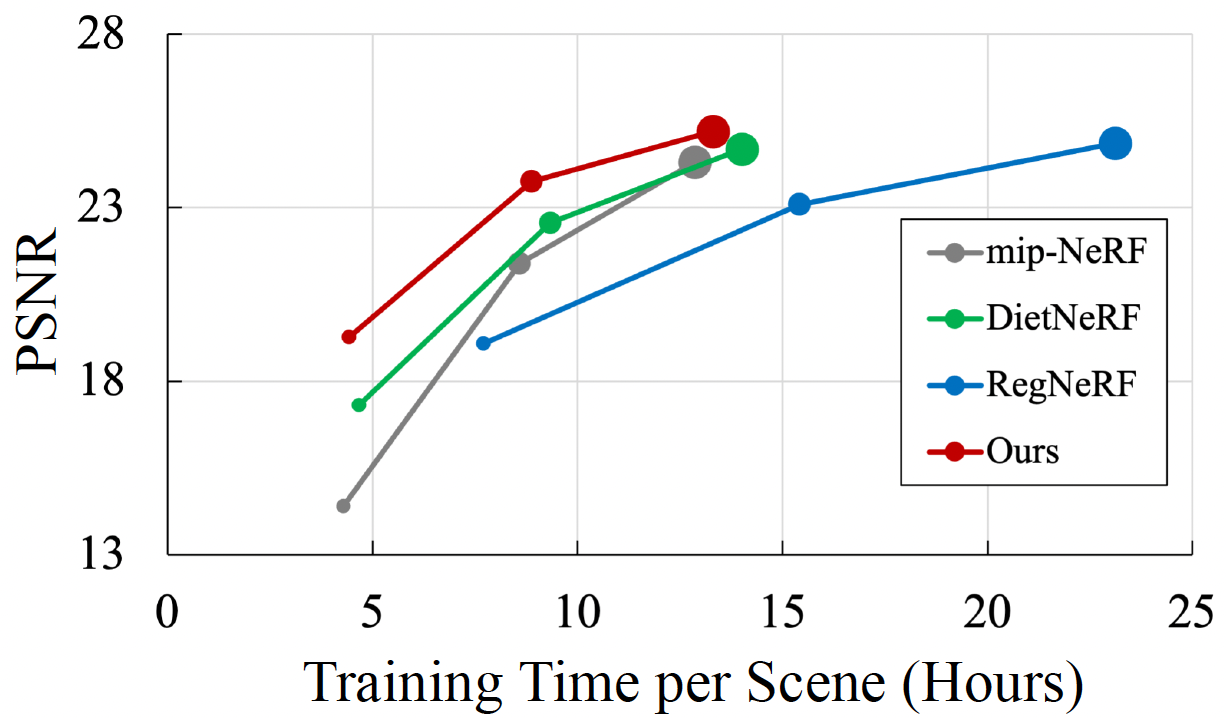
Results
DTU 3-view
LLFF 3-view
Blender 4-view
Citation
Acknowledgements
This work was supported by NRF grant (2021R1A2C3006659) and IITP grants (2021-0-01343, 2022-0-00953) funded by Korean Government.